This is post covers how I built the Backtesting Engine which supports all of my research. I’ve designed a Backtesting Engine to experiment with financial datasets at scale on Amazon Web Services (AWS).
Project Goals
I started this project as I wanted to improve my understanding of financial markets and showcase technical expertise through the documentation of progress and the tracking of decisions.
To explore the benefits of using Cloud Services (AWS specifically) to scale strategies and permutations. Scaling up and performing multiple experiments lowers the time to analyse the output and produce actionable insights*.
Finally, to research and experiment in the technologies I enjoy, C#, .NET and AWS, in a field of interest I find fascinating Quantitative Engineering.
*Just a quick note, this is not trading advice, or guidance for how to trade. These articles are focused on historical datasets and backtesting gives no guarantee of future performance of discussed strategies. All trading decisions are your own.
This blog post will primarily delve into the technical challenges, however, before delving into those details I will start off going through some of the fundamentals of Backtesting.
What is Backtesting?
Backtesting is the process of validating a trading strategy against historical data and should simulate market conditions with enough detail to ensure realism. A backtesting system continuously analyses and executes trades accurately.
Trading strategy
A trading strategy decides the entry and exit points of trade, and in theory, strategies that worked well in the past could work well in the future. However, markets are continuously changing in volatility and momentum, so this is not always the case.
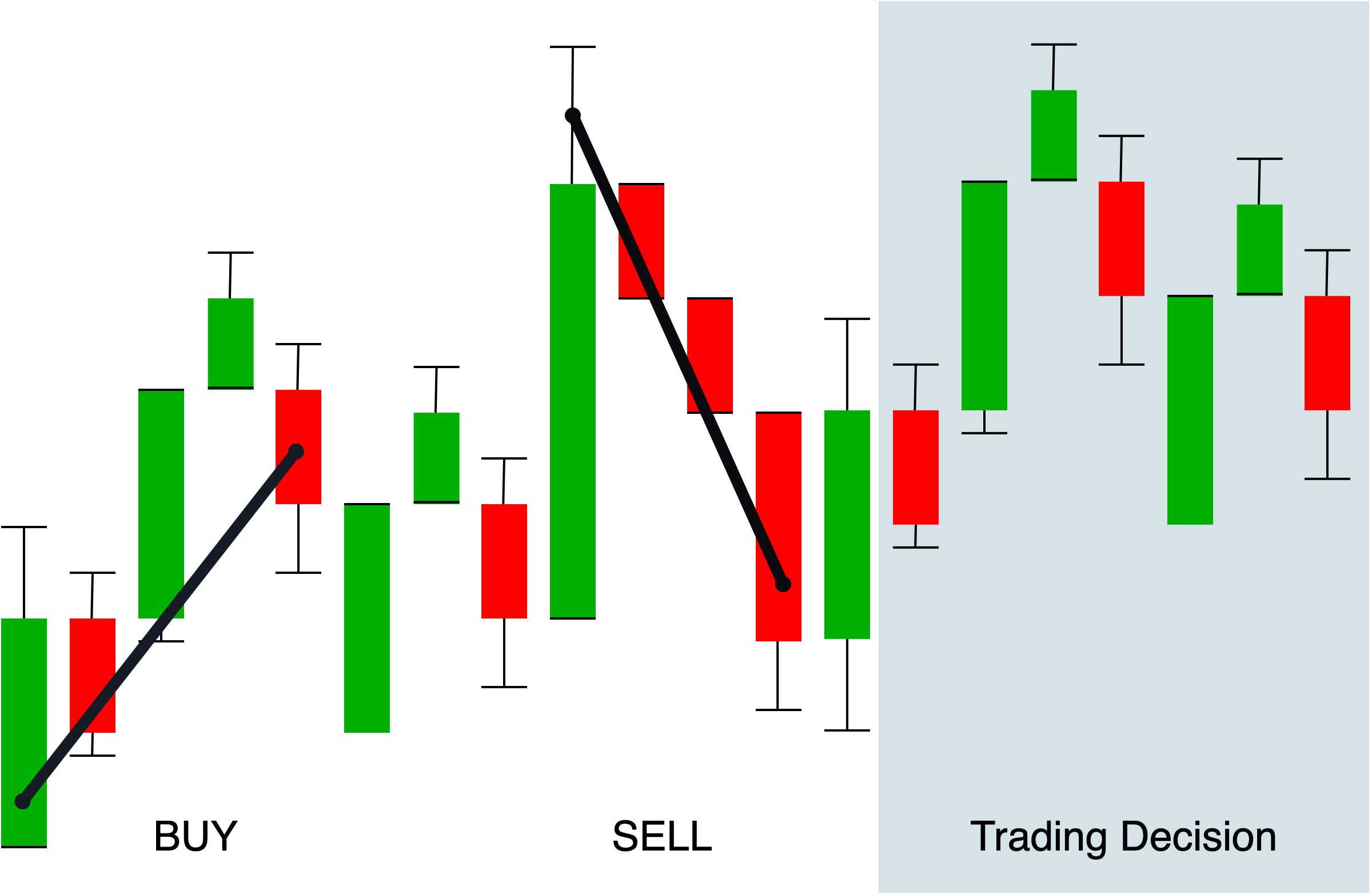
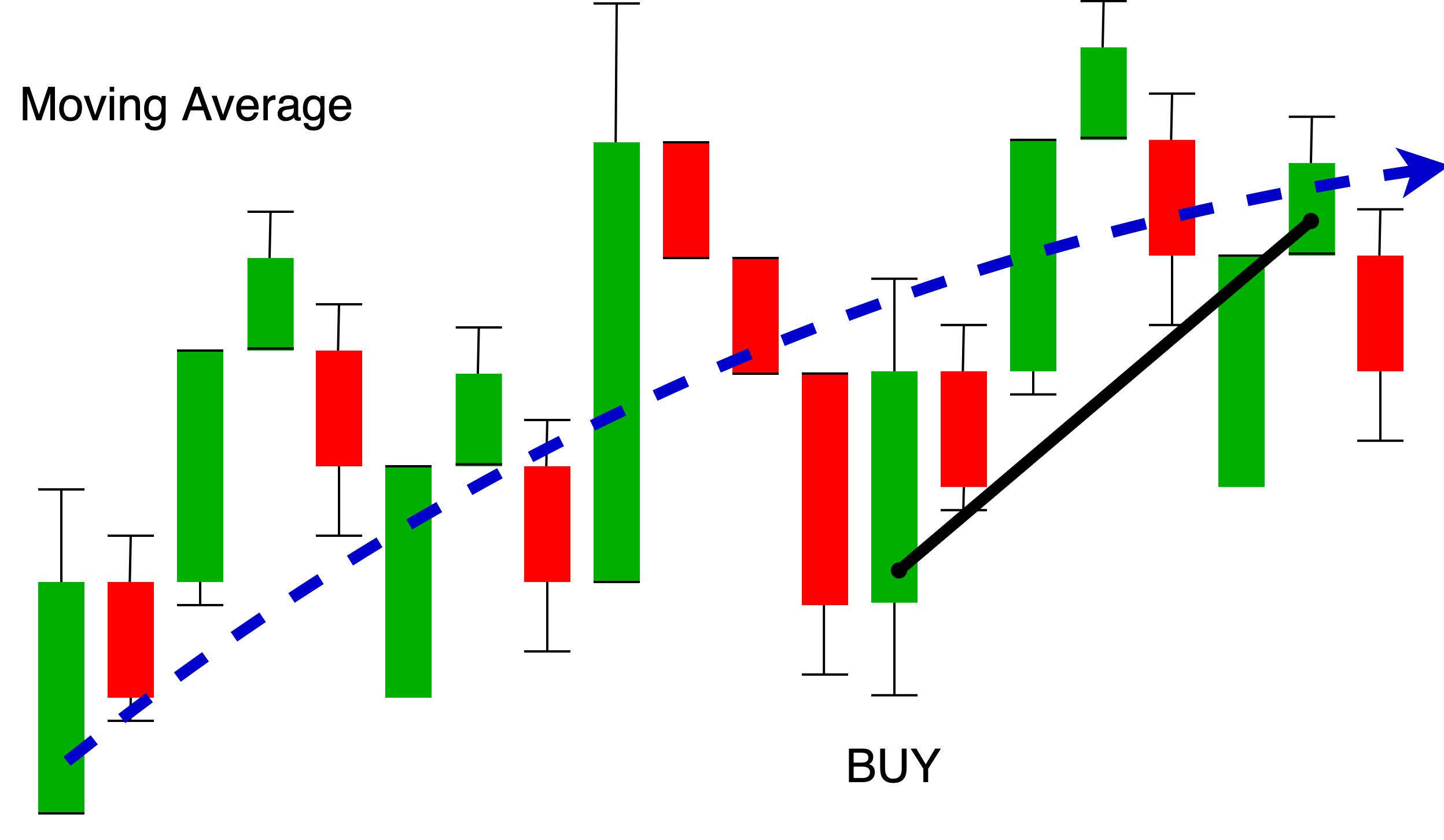
To give an example, a strategy could define conditions to BUY an asset if it’s value falls significantly below the 10 day SMA (Simple Moving Average). This would be under the assumption that every price has equilibrium and a reversion to the mean.
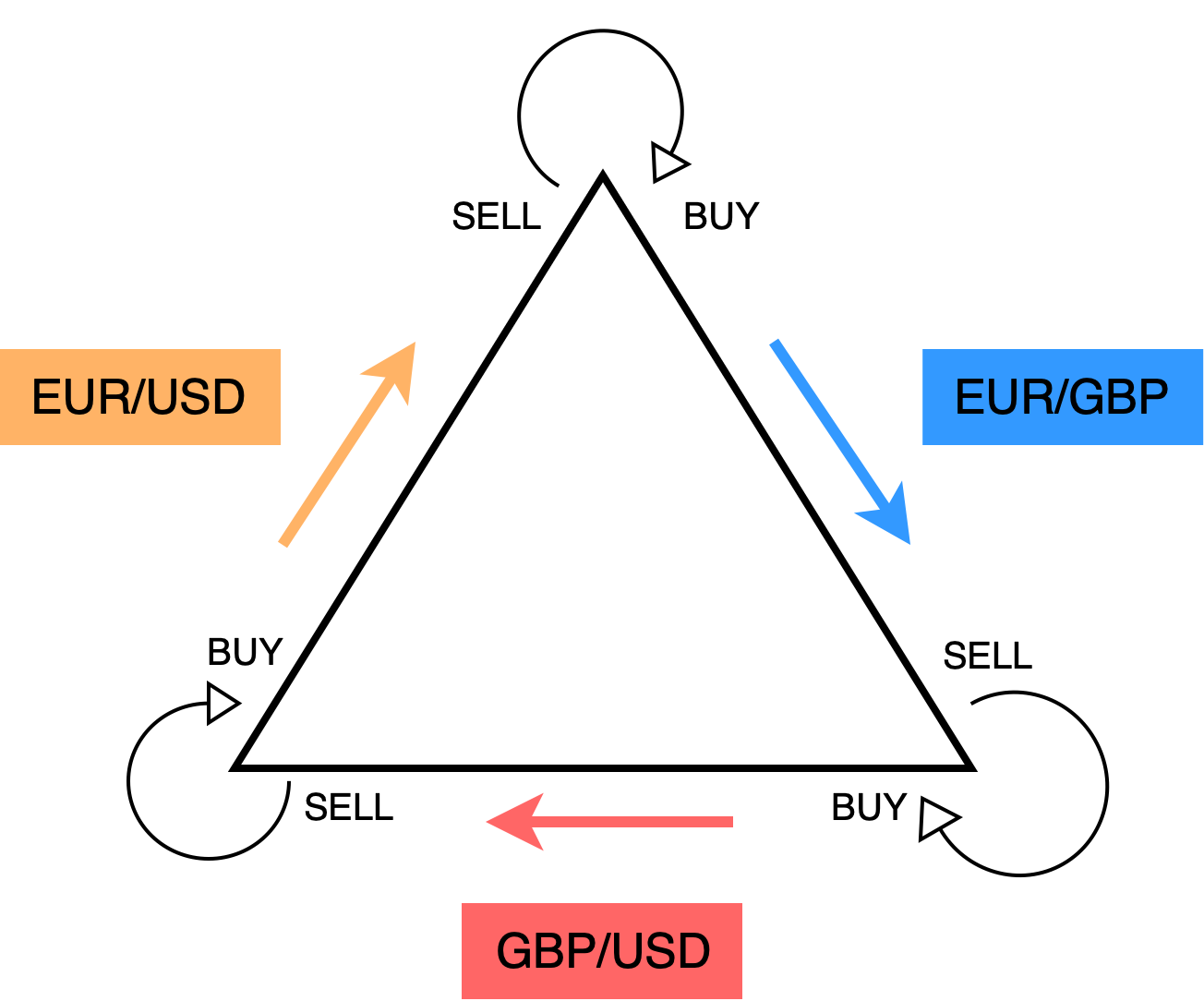
The backtesting engine will support the ingest of multiple symbols and synchronise them to enable the experimentation of arbitrage strategies. Arbitrage is a method of exploiting price disparity in the markets. In summary, you buy and sell an asset (currency in this instance) that is currently diverged but extremely likely to converge.
I’ll cover more on individual strategies after I have built the backtesting system.
Terminology
There are thousands of terms across finance and software engineering. I’ll explain unique and ambiguous terms as I go.
Financial instruments are monetary contracts between parties, and their type will depend on the asset class they are in. In the Foreign Exchange, an instrument is typically referred to as a currency pair, and across the Stock exchange, a stock symbol. You’ve also got indexes, bonds, ETFs, crypto, and so on with their nuances. You’ve also got indexes, bonds, ETFs, crypto and so on with their own nuances. To simplify, the backtesting engine will refer to any instrument as a symbol (eg. EUR/USD, FTSE100, UK1YR).
I’m primarily focusing on the Foreign Exchange Market (also referred to as Forex, FX, or currency market) to begin with. However, the backtesting engine will work with any financial asset as long as the tick data is in the same format.
# Expected CSV format
# DateTime, Ask, Bid
YYYY-MM-DD hh:mm:ss.fff, 0.00, 0.00
Technology
I’m using a range of technology to build the backtesting engine, primarily C# .NET with AWS and ElasticSearch. I’m going to talk through why I’ve picked these technologies and document their use.
I’m also hosting the source code publically on Github, https://github.com/mccaffers/backtesting-engine.
.NET
I’m very familiar with C# and .NET so I’m able to quickly prototype and experiment with new ideas. C# is a powerful and widely used multi-paradigm programming language. .NET is a cross-platform successor to the .NET Framework which is free and open-source used in gaming, websites, mobile applications, and more. I’d like to explore C++ in the future once I’ve built a prototype.
Unit Testing
I’ll be using Xunit and Moq to create automated tests that focus tests on specific parts of the application. This means I can test specific parts of the application (eg. ingest, consumers, strategies) and reduce the chances that I introduce any errors. I say reduce as it’s hard to get complete test coverage of all of the possible scenarios but I intend on trying to cover as many as possible. Unit tests will also be complemented by static code analysis (via SonarCloud) to provide even more reassurances.
ElasticSearch
Elasticsearch is a world-class free text search tool that can convert large volumes of data into meaningful visualizations with complex relationships. It’s open-source and free. I’m using the cloud-managed Elastic service on https://elastic.co which provides a centralised data store and using Kibana to visualise trading results.
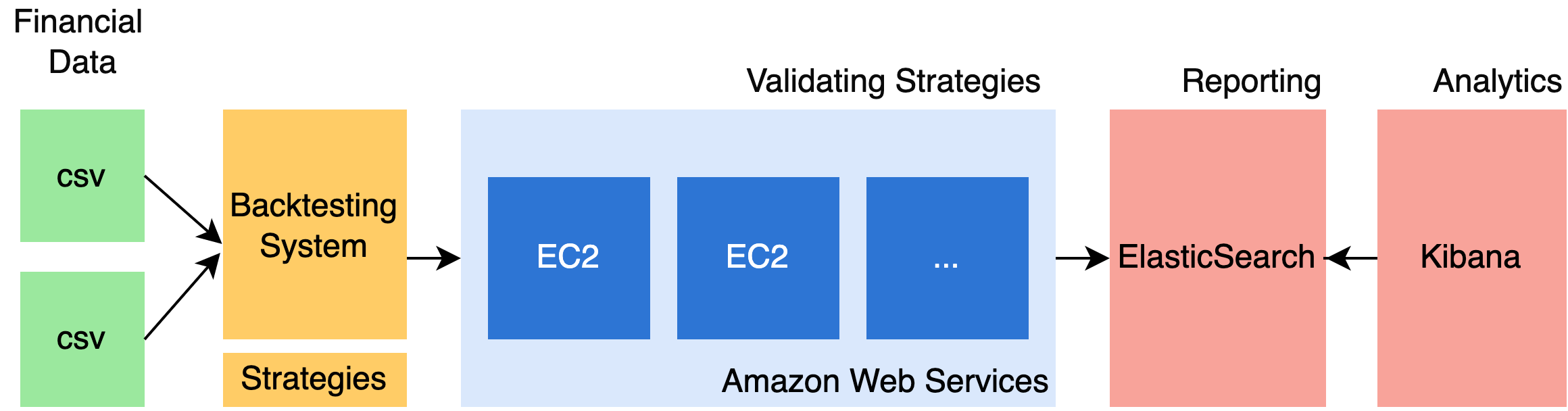
Amazon Web Services
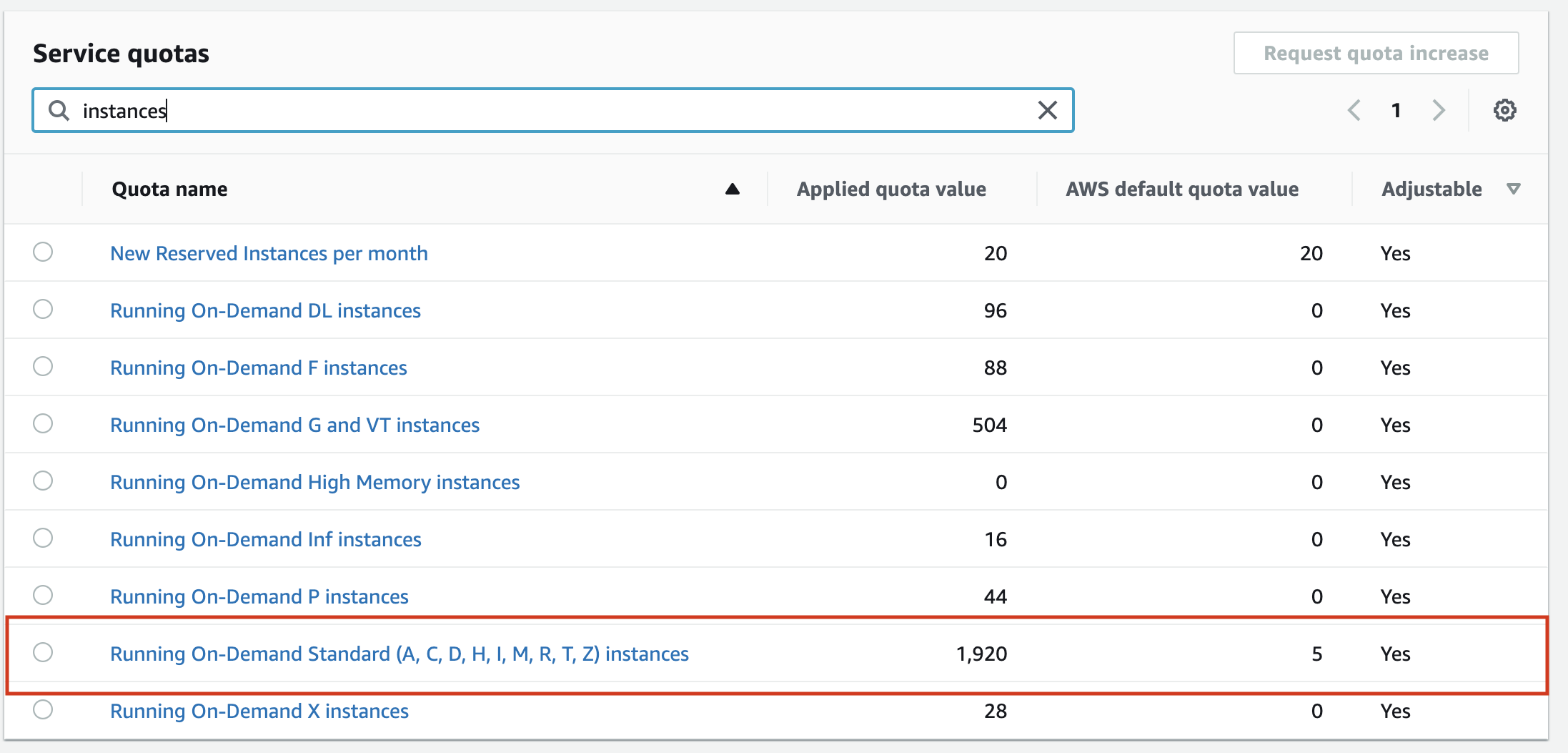
I’m using Amazon Web Services (AWS) as a cloud provider to validate multiple permutations in parallel. Testing depends on AWS’s quotas, which are currently set to a maximum of 2000 EC2 instances at once for my AWS account.
Approach
- Create a C# application that can ingest multiple symbols (.csv files, 1..*) and synchronise the events
- Add static code analysis and unit testing
- Ensure the application has a realistic and configurable trading environment
- Support the injection of trading strategies
- Setup reporting and output trading results for analysis and visualisation
- Develop deployment scripts to run at scale on AWS
Monthly Updates
I will be adding updates to this page until I complete the backtesting system. Monthly updates will focus on the technical development and implementation of the financial backtesting system. I’ll explain and share snippets of code, however, you will need to be familiar with software engineering to get the most out of the updates.
- November 2021 - Creating the skeleton C# ingest application
- December 2021 - Adding unit tests and code analysis
- January 2022 - Building the trading environment
- February 2022 - Ensuring the trading environment is realistic
- March 2022 - Dependency injection and Reporting
- April 2022 - Deploying to AWS
November 2021
In this update I focus on the initial development of the C# ingest applicationCreating a .NET application
It’s straightforward to create a new .NET application, you just need the .NET SDK and then you can create a skeleton application dotnet new console.
ryan@MacBook project % dotnet new console
The template "Console App" was created successfully.
Processing post-creation actions...
Running 'dotnet restore' on /Users/ryan/dev/project/project.csproj...
Determining projects to restore...
Restored /Users/ryan/dev/github/project/project.csproj (in 110 ms).
Restore succeeded.
ryan@MacBook project % ls -l
-rw-r--r-- 1 ryan ryan 105 14 Nov 07:00 Program.cs
drwxr-xr-x 7 ryan ryan 224 14 Nov 07:00 obj
-rw-r--r-- 1 ryan ryan 249 14 Nov 07:00 project.csproj
Ingest of CSV files
To begin with, I start working to develop the capability to ingest multiple CSV files. It’s quite easy to read a single file, and even easier if you want to read the whole file at once. For example, System.IO.File.ReadAllLines() reads the whole contents of the file and returns a string[]. I’m working with yearly symbol CSV files which are over 1GB each so I have to be cautious with loading everything into system memory.
There are several system options for reading files in C#, such as System.IO.File and System.IO.StreamReader.
Looking into the Microsoft Reference and I discovered that the File.ReadLines is just an abstraction layer over the System.IO.StreamReader class, so I’ll the system will use a StreamReader.
Microsoft Reference Sources, System.IO.File.ReadLines (file.cs), System.IO.StreamReader.Readline (streamreader.cs)
Streaming CSV files
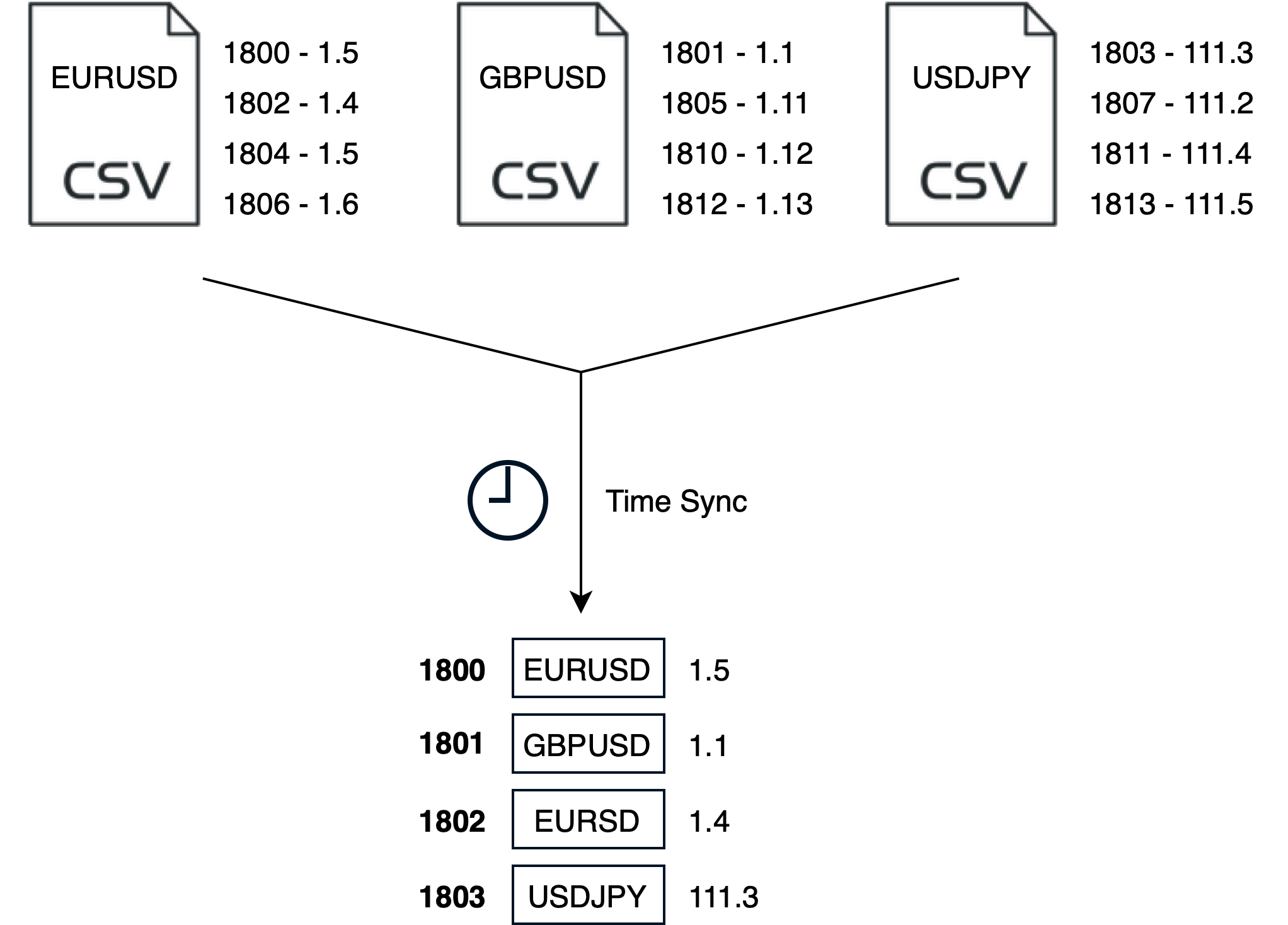
To keep track of each StreamReader instance the system will create a Dictionary per Symbol.
This is perhaps a nonconventional use of the StreamReader, as you woul normally wrapped it with a using statement to handle the closure and disposal of the StreamReader class. However, I need to keep the StreamReader instances open for each Symbol so that I can read each line, pause and review the time difference between the events in the CSV files, and then repeat.
| |
Each line in the CSV has a timestamp relating to the symbols ASK and BID price. The above code reviews each line of the csv and then populates a buffer in time order. I’ve simplified it in the diagram below.
Concurrency
To make the system as performant as possible I’m using BufferBlock with asynchronised methods to ingest and consume in parallel. This means that the system can make use of as much of the system resources as possible without tieing IO and CPU resources together. The bufferblock is part of the System.Threading.Tasks.Dataflow namespace and is the preferred way to write multithreaded and parallel code.

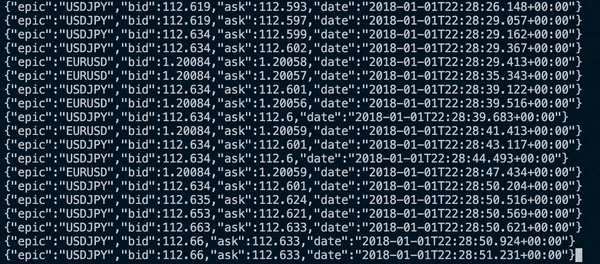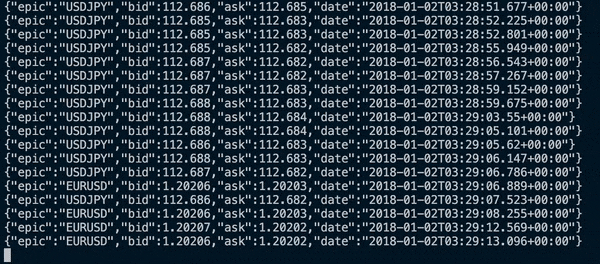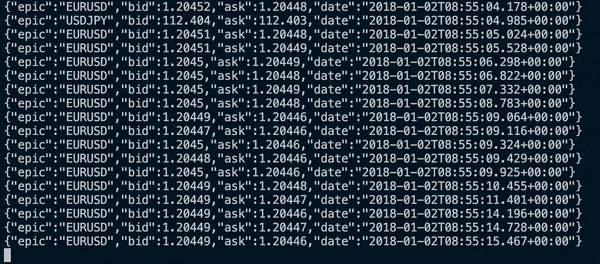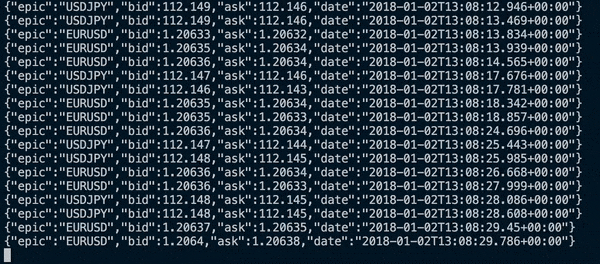
I created a placeholder consumer to read off the BufferBlock and print to line the received DataFlow objects.
| |
I was able to visually see that the symbols have been placed onto the buffer in time order. I’ll confirm this programmatically in the next update using unit tests.
December 2021
Adding unit tests and code analysisXunit & Moq
I’ve added Xunit and Moq to unit test the codebase. These tools help to ensure consistency as you make changes. I’ve chosen Xunit over other .NET test frameworks as it has high readability, simplicity, and extensibility (with Fact and Theory attributes).
Going forward I’ll execute tests before running the application. I’ve set up an entry point of the application to run tests before running the application (Line 4 in the code snippet below).
| |
set -e instructs bash to immediately exit if any command has a non-zero exit status and .NET returns status 1 if any test fails. This means the application will not run and leave a message in the terminal highlighting the tests that are failing.
Xunit Theory
The Theory attribute of Xunit allows you to validate multiple variables and scenarios in a single test.
In the test scenario below I am validiating various data input and seeing how the ingest component of the backtesting engine responds. Out of the five inputs, only one should produce a valid price object on the buffer, and the system should be protected from errors.
This can be broken down into two parameters, the first, an integer describing how many events should be added to the buffer.
InlineData(expected amount of items in the buffer,string to be ingest)
| |
The unit test outputs Total tests: 5. Passed: 5. Failed: 0. Skipped: 0 and gives me more confidence that the system is able to cope with troublesome data if it was to appear.
SonarCloud
SonarCloud provides a detailed analysis of your codebase and is free for open-source projects. It helps to identify vulnerabilities and code duplications. It also has metrics for technical debt and unit test coverage. These assessments help to ensure I’m writing good quality code and reduce the overall maintenance cost of the application.
I’ve added SonarCloud to review trading engine via github actions. See a snapshot below from SonarCloud showing a number of code smells in the application (at this point in time) that requires attention.
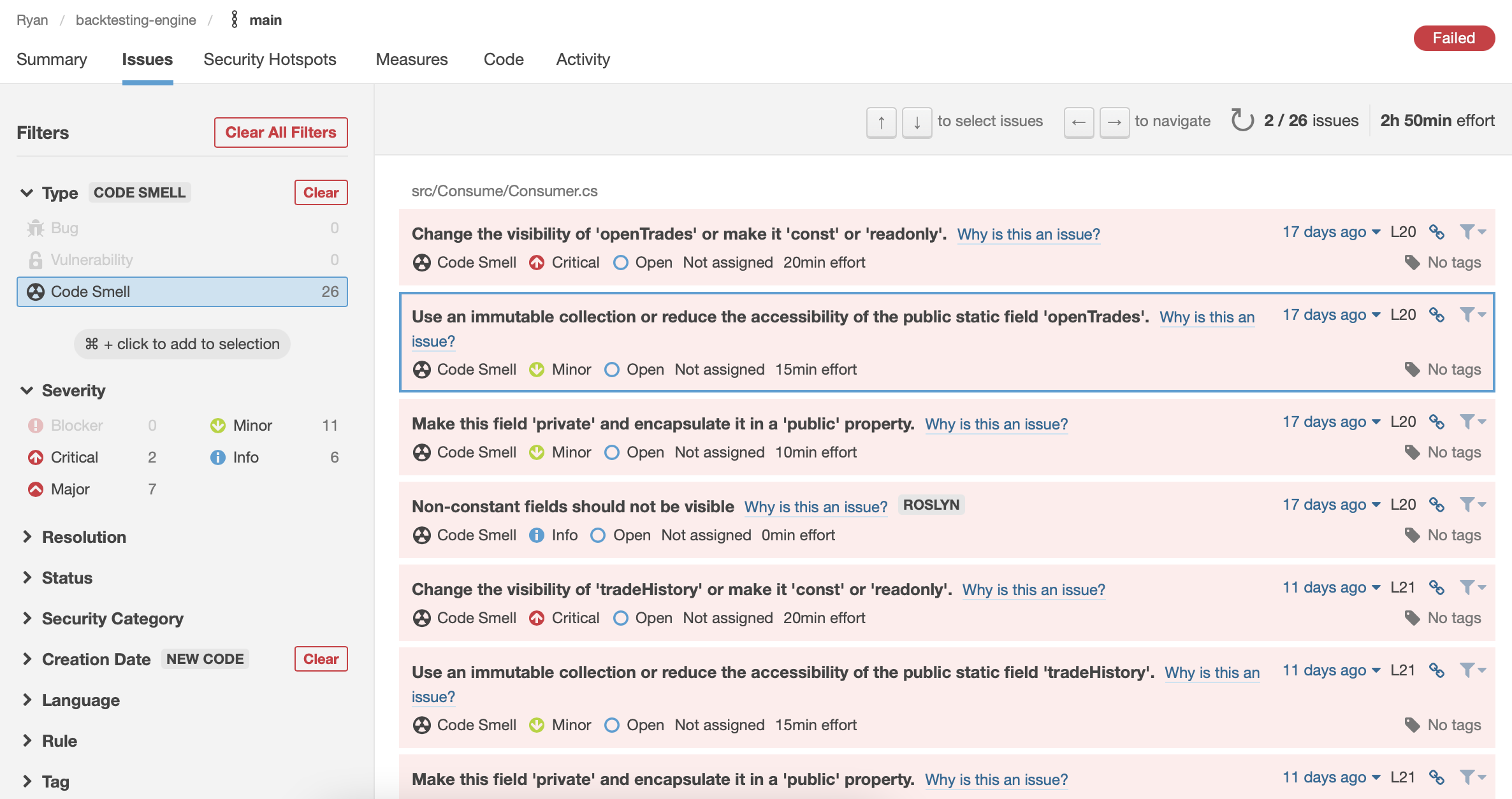
A public link to view SonarCloud analysis is available, https://sonarcloud.io/project/overview?id=mccaffers_backtesting-engine.
January 2022
Building the trading environmentModels
Before I could start building a trading environment I created several C# models to contain price and trade data. These C# models are classes with properties definitions.
public class PriceObj {
public string symbol { get;set; } = "";
public decimal bid { get;set; }
public decimal ask { get;set; }
public DateTime date { get; set; }
}
The system creates a new PriceObJ object for every event (every line in the CSV).

Memory Management
It’s useful to understand how memory is allocated and managed, as there will be thousands of events ingested every minute. C# has managed memory allocation and deallocation. Deallocation is through a process called garbage collection.
Trading objects are managed and released after use, however I need to keep an eye on how much the BufferBlock fills up and consumes memory, and also ensure my injected class have appropriate lifecycles.
Data models:
PriceObj- The Price object contains the symbol, time, bid, ask and volume valuesOHLCObj- The OHLC Object contains open high low close values. OHLC values are typically used to illustrate movements in the price of a financial instrument over time.TradeRequestObj- The Trade Request Object contains the request parameters to open a trade, eg. the direction (BUY/SELL), size of the trade, opening level.TradeHistoryObj- The Trade History Object contains previous trades that have been closed, values taken from Trade Objects (TradeObj)TradeDirection- The TradeDirection Object is a string enum, defining the direction of the trade.
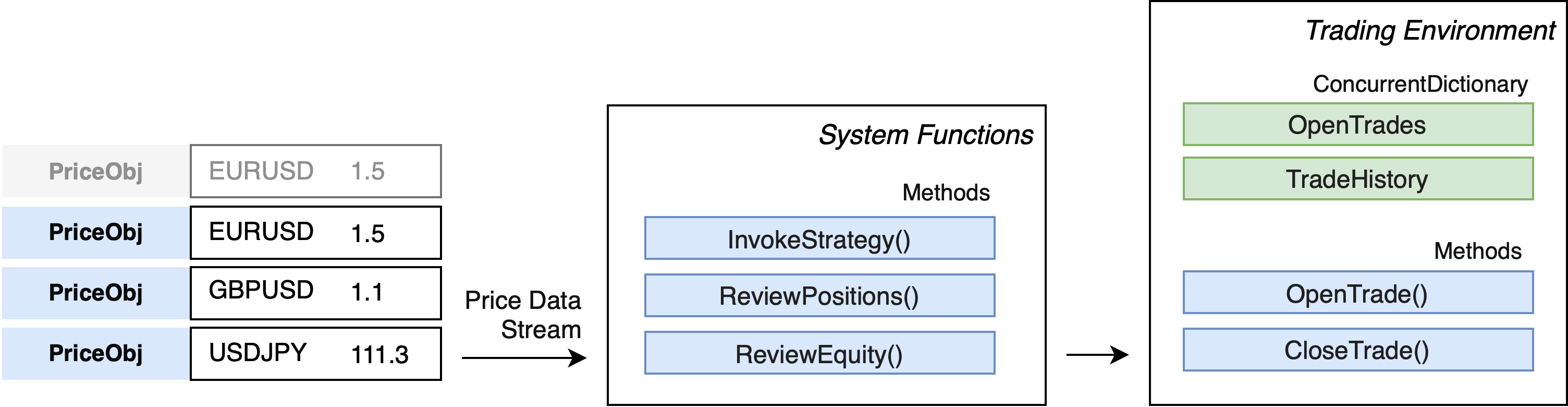
Trading Environment
Every PriceObj event is passed to a number of system functions:
InvokeStrategy- This method determines whether to open a new trade based on the parameters in the strategy.ReviewOpenPositions- This function determines whether any of the open trades have reached the definedTAKE PROFIT (TP)orSTOP LOSS (SL)values.ReviewEquity- This function determines whether the account equity has breached its defined limits. If so, the system will report out and close.
Invoke Strategy
At present and for testing, the strategy function opens a trade randomly. The function calls the OpenTrade method, passing a few parameters about the direction and size of trade.
| |
Open Trade
At the moment there is no validation on the OpenTrade() method. All trade requests are acted upon. Every trade request takes instruction of the trade, eg. size of the order and the direction. The function populate the openPositions dictionary so the system can keep track of open trades.
Program.openTrades.TryAdd(reqObj.key, reqObj);
I’m using a ConcurrentDictionary to have a thread-safe Dictionary to keep track of the open trades and closed trades. A C# Dictionary is a collection of key/value pairs, and a ConcurrentDictionary can be accessed by multiple threads concurrently.
ConcurrentDictionary<string, OpenTradeObject> openPositions
ConcurrentDictionary<string, TradeHistoryObject> tradeHistory
As an example, the screenshot below demonstrates how the backtesting engine checks if the dictionary already has an open trade for a particular symbol, and if not tries to open one. A ConcurrentDictionary has a TryAdd method which checks if the key already exists, avoiding duplicate trades.

Review Positions
The review positions function checks if any of the open positions have reached their STOP or TP levels. The function checks which direction the trade is and then determines the conditions (see Lines 56 and 63 below). If they have, the system closes them out by calling the CloseTrade() function.
| |
Close Trade
The Close Trade method has three functions:
- Calculate the amount of PL (Profit/Loss) of the trade
- Remove the trade from the openPositions dictionary
- Add the trade into the tradeHistory direction
| |
February 2022
Ensuring the trading environment is realisticRealistic Environment
I’ve spent time focusing on ensuring that Long and Short positions are correctly positioned using the BID and ASK price.
- The bid price refers to the highest price a buyer will pay
- The ask price refers to the lowest price a seller will accept
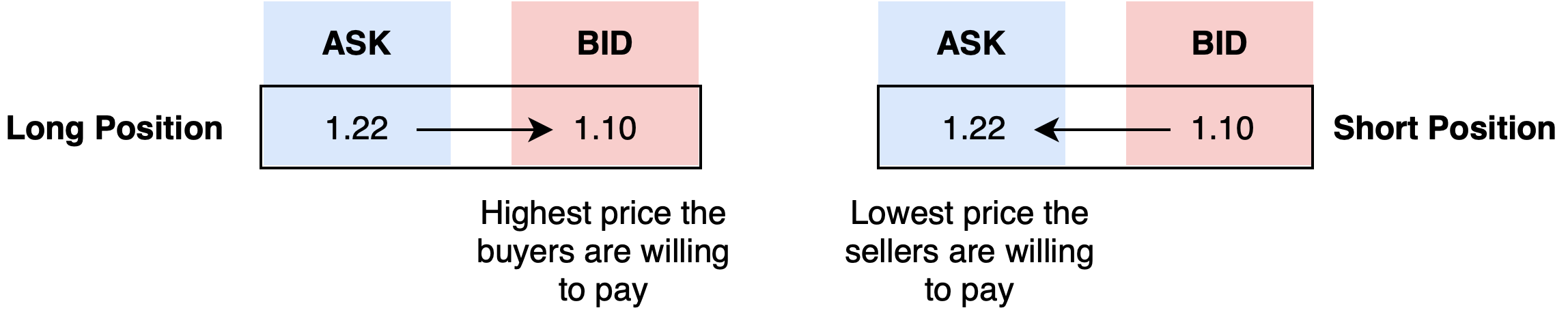
The TradeRequestObj determines the correct price based on the direction of the trade. The level field cannot be changed outside of the class (private property).
| |
The system is taking the opposite price (BID/ASK) or (ASK/BID) for the close and calculating the difference to get the Profit/Loss and the close value is continuously calculated.
| |
Decimal
The system is using decimal as the numeric type for all of symbol price data and calculations. Decimal is regarded as the best type to be used in financial calculations where we do not want end rounding, and minimizing rounding errors where they are necessary.
Slippage
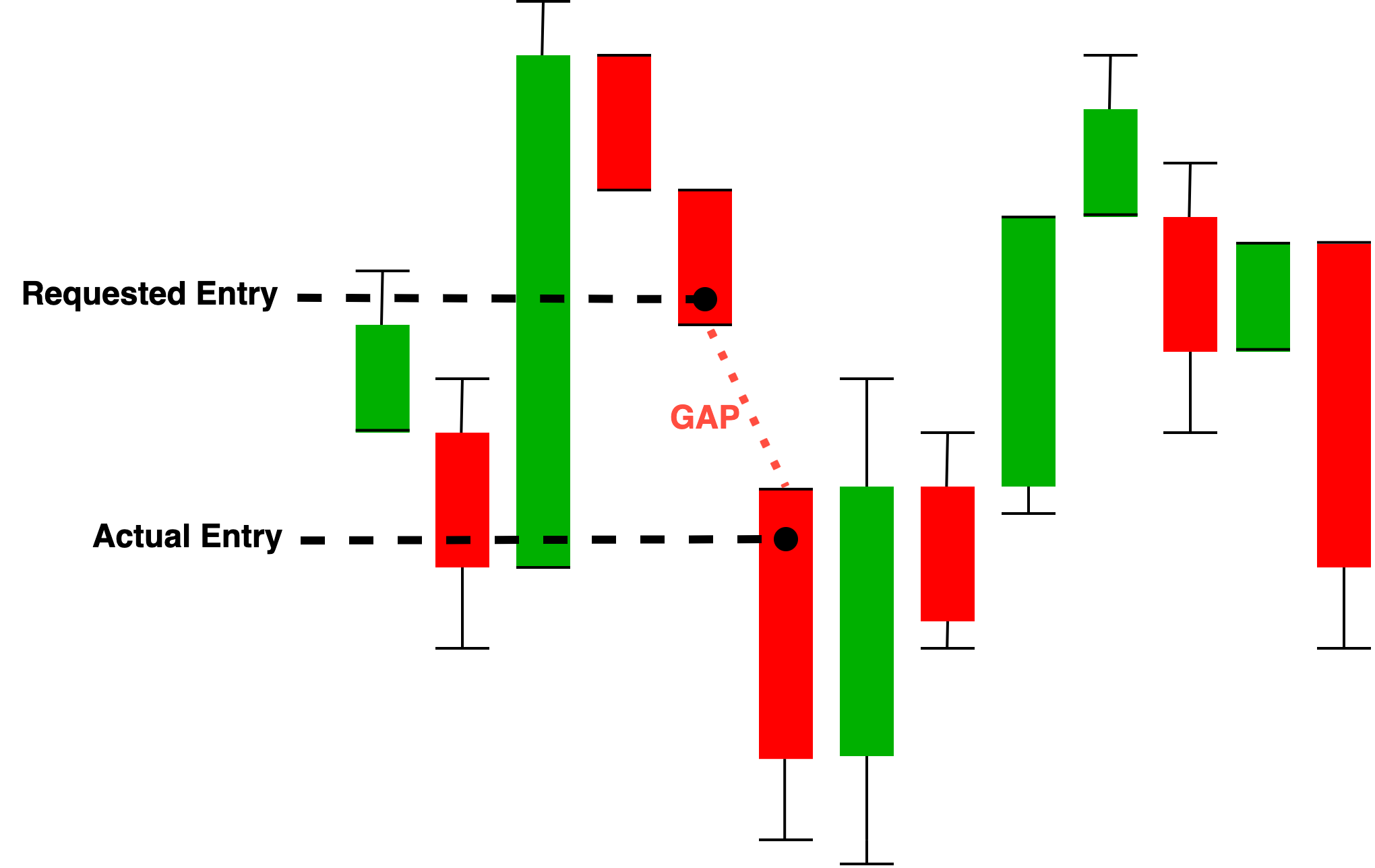
I’ve added a function to the TradeRequestObject to add slippage to the entry price. To begin with I’ll hard code one PIP (percentage in point) as slippage per every trade. I’ll move this later to be configurable variable.
| |
March 2022
Dependency injection and ReportingEnvironment Variables
The backtesting engine takes in system and trading parameters via the environment file .env/local.env. These environment variables are pulled into the local deployment script ./scripts/run.sh and ./scripts/aws.sh.
# .env/local.env
symbolFolder="tickdata"
symbols=EURUSD,GBPUSD
accountEquity=500
maximumDrawndownPercentage=50
strategy=RandomStrategy
reportingEnabled=true
In the future the AWS deployment script will be able to adjust the trading parameters, and loop conditions prior to deployment to test different strategy variations.
Dependency Injection
The extension method RegisterStrategies loops the strategy names listed in the environment variables and verifies the class exists and implements the IStrategy interface. An implementation of IStrategy must must implement an Invoke(PriceObj priceObj).
| |
The service is then registered as part of the initial start of the application inside Main(string[] args) in Program.cs.
| |
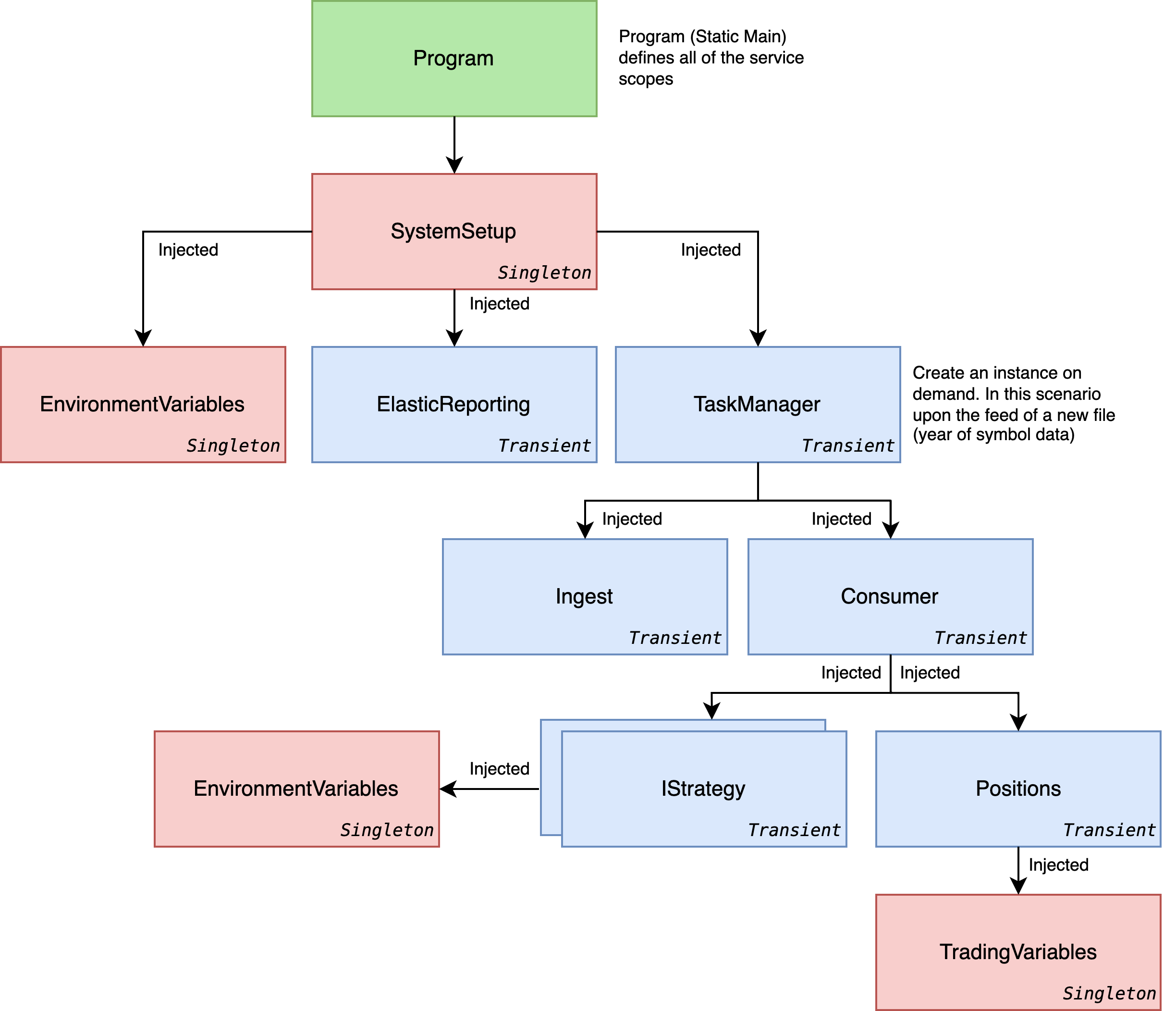
The IStrategy dependencies are injected in the Consumer, and when there is available data in the buffer .Invoke(priceObj) is called.
| |
This is important to know as it allows you to define multiple strategies in parallel by seperating strategies in the environment variables with a string strategy=RandomStrategy,CloseOnFridays.
CancellationToken & Tasks
A CancellationToken enables cooperative cancellation between threads. To repeat, the trading system runs two threads to ingest from CSV, and consume (which performs trading). I needed to ensure that both ingest and consumer failover if either has an exception.
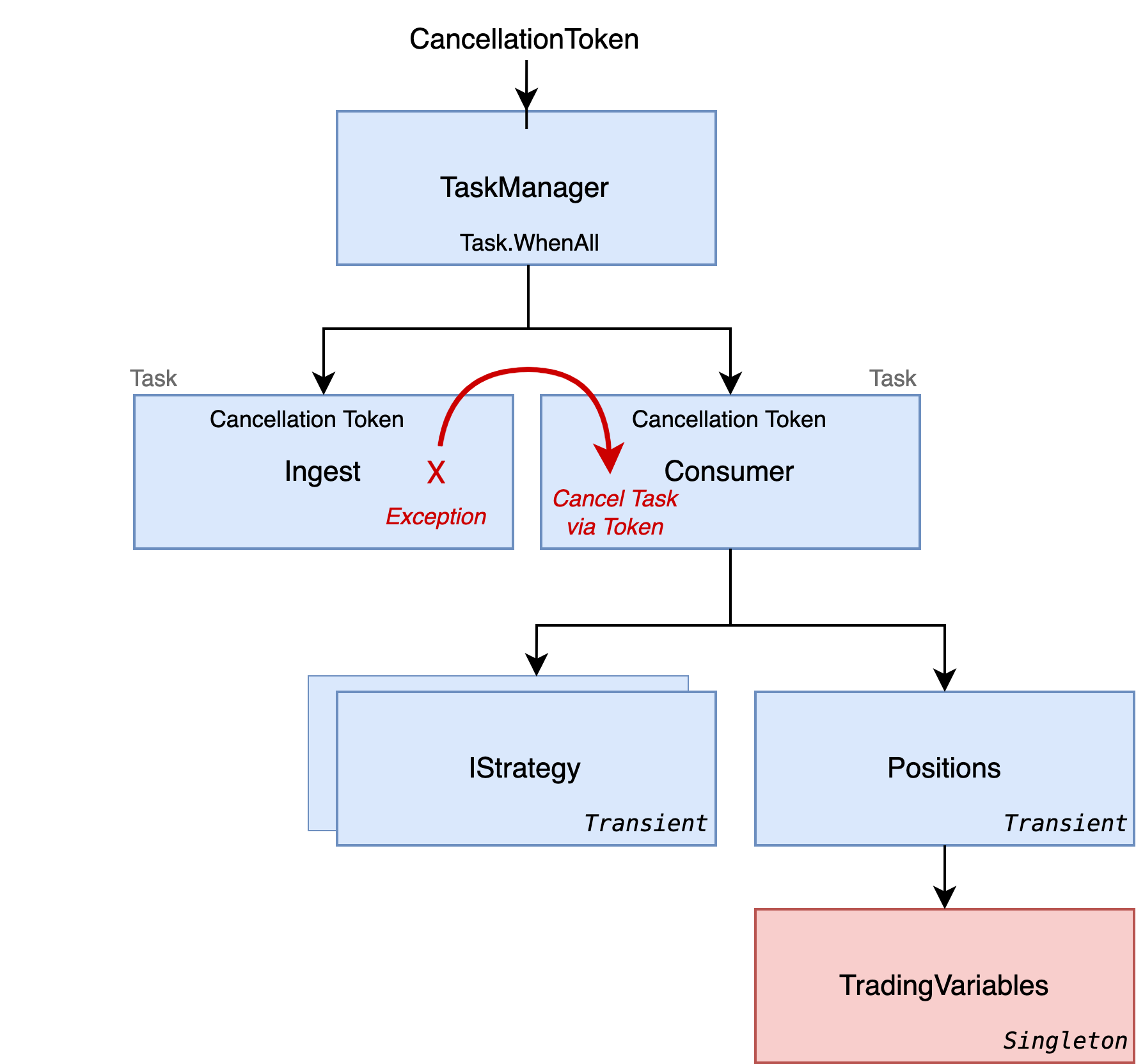
So the ingest and consumer are passed a cancellation token which is checked on the event loop to ensure that the other has not thrown an exception b checking the ThrowIfCancellationRequested() method.
| |
ElasticSearch
I’m using ElasticSearch to store trading reports and Kibana to visualise the trading performance of various strategies. The trading system uses the .NET ElasticSearch package called NEST (the official high-level .NET client of Elasticsearch). With the NEST package I can send trading objects directly to elastic.
I set up a connection pool with elasticsearch and made a number of methods to batch and send updates.
| |
EndOfRunReport(string reason)is invoked when the either the system reaches the end of the file or if a trading condition triggers the end of the run.SendStack(MyException message)is invoked when the system experiences an unexpected exception.TradeUpdate(DateTime date, string symbol, decimal profit)is called every time a trade has been closed, due to the high frequency of trade updates the updates are batched for 5 seconds.BatchTradeUpdate()is called if more than 5 seconds have passed since the last bulk upload.BatchTradeUpdate()sends all of the queued trading events to elasticsearch. The method calls the BulkAsync on the elastic client without using await so the request is performed in the background without blocking the main trading thread.
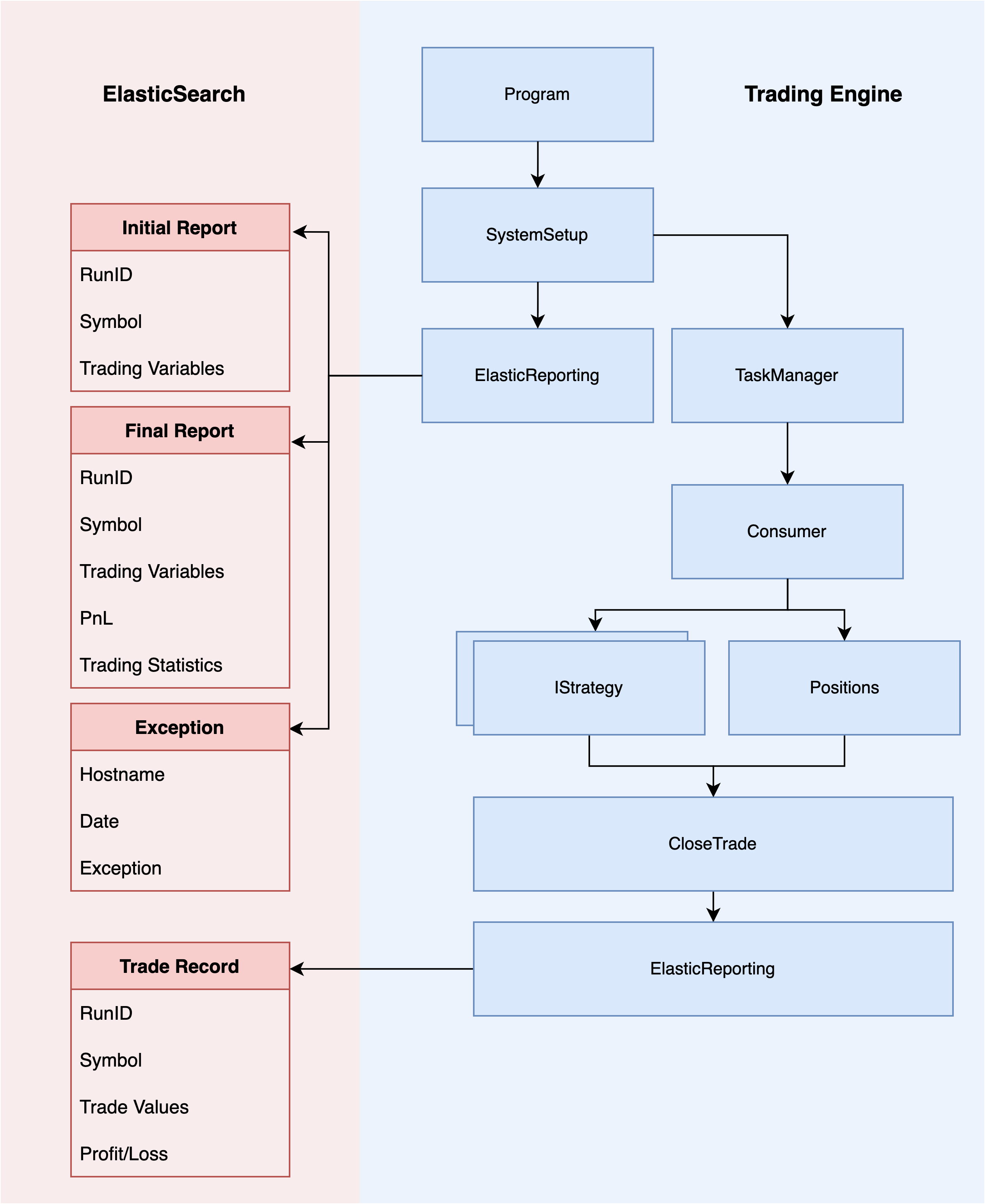
Observability with ElasticSearch
I plan on deploying thousands of experiments on AWS and the observability platform on elasticsearch provides a way of catching any infrastructure or application error messages across all of the EC2 instances. I’m using the filebeats agent to monitor system and application log files.
To do this I’ve taken the installation steps from https://www.elastic.co/guide/en/beats/filebeat/current/setup-repositories.html and added them to the AWS.sh deployment script.
| |
EC2 instance now has the Filebeats agent running but needs it’s config yaml to be updated to reference the application logs. This reports out infrastructure and dotnet errors (eg. uncaught exceptions, eg. OutOfMemoryException or Segmantion faults).
| |
This is important as trading runs will obviously end if the system has a fault error skewing the results. After seeing any faults I can take steps to protect the system to prevent it reoccuring.
As an example during testing I discovered that some of the EC2 servers were running out of space while running through a trading run.
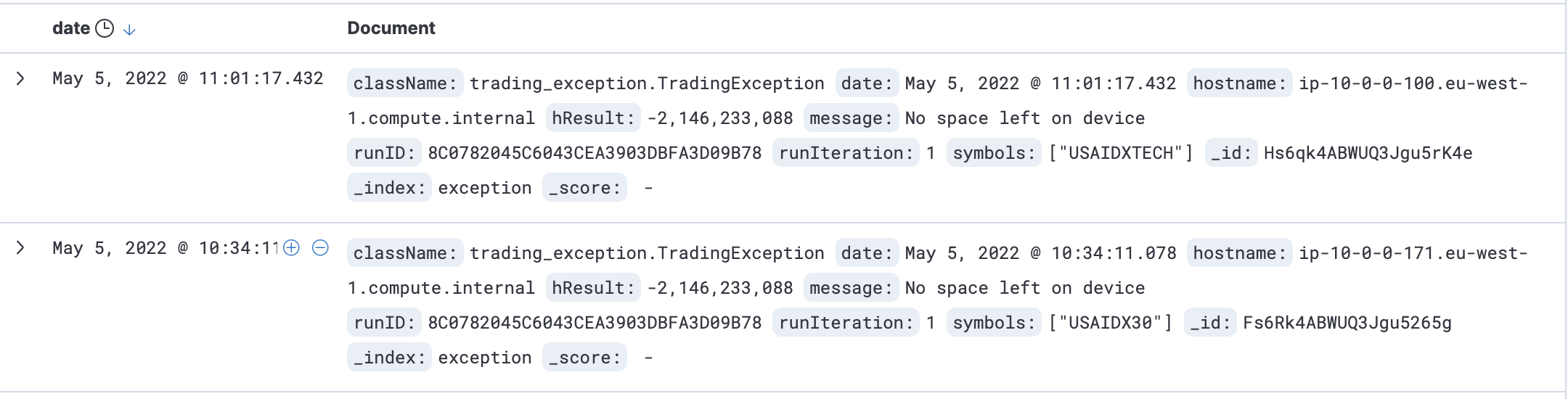
It would have been time consuming and error prone to check each individual node so through ElasticSearch I could see all of the errors in one place.
Environment Variables
The trading systems uses a number of environment variables to execute the trading run. For consistency across the application the environment variables are pulled from a single utilities class.
I’ve wrapped the System.Envrionment method to throw if any expected evnrionment variable is missing as the method System.Environment.GetEnvironmentVariable(string) returns an empty string if the environment variable is not present which could cause errors if it was to be expected further downstream.
| |
With this designed, parts of the system can call Environment.Strategy which is a pre-popualated string variable from the environment.
April 2022
Deploying to AWSScaling up
Now that the system can trade and validate strategies locally I need to develop scripts to deploy ontop of Amazon Web Services (AWS). This will allow the trading engine to test strategies at scale.
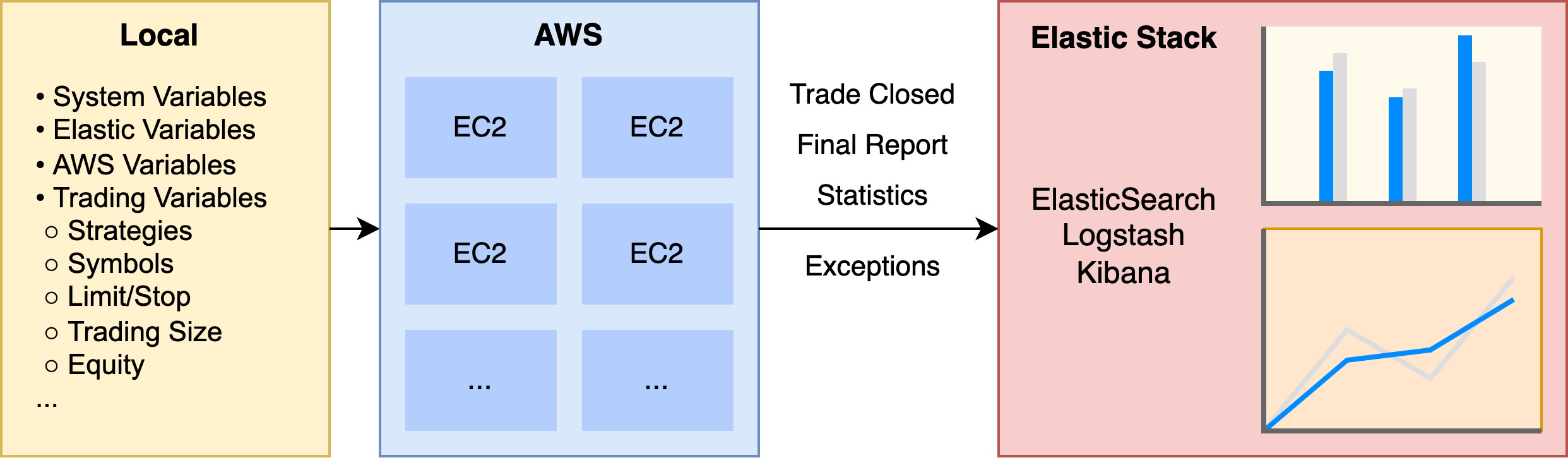
The deployment scripts
The trading engine takes in an environment file .env/AWS.env which defines the AWS parameters for the trading run (eg. the instance type) and associated fields (subnet group, security group, IAM roles, etc.)
| |
These environment variables are pulled into a bash deployment script ./script/aws.sh which builds an array of strategies and symbols to iterate over.
I’ve defined a number of local variables inside the bash script to configure the trading parameters (eg. stopLossInPipsRange, limitInPipsRange).
The sequence is built up by a {start value} {increment value} {end value}
So 10 2 20 would build a sequence of 10 12 14 16 18 20.
| |
The strategies function iterates over every item in the strategies array.
In the example above you can see there is only one strategy defined, RandomStrategy, but there could be multiple. You can also define multiple strategies inside of a run.
strategies=("RandomStrategy")- Validates one strategystrategies=("RandomStrategy,CloseOnFridays")- Validates two strategies togetherstrategies=("RandomStrategy","CloseOnFridays")- Validates two strategies independently
The deployment script takes all of the environment variables defined above and populates a template:
| |
The envsubst program substitutes the values of environment variables and I’m directing it’s function against the awstemplate.sh file and outputing the result into the data.sh script. The AWS CLI then takes this file in as the user-data which is run when the EC2 starts.
| |
The image resolve:ssm:/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-arm64-gp2 refers to the latest AWS AMI ARM instance, so I don’t have to worry about building a specific image for this. I’m keen to always take the latest and most secure version Amazon provide. You can see the template script in full here, https://github.com/mccaffers/backtesting-engine/blob/main/scripts/awstemplate.sh
As a result the backtesting engine can now deploy on top of EC2 instances to validate a trading scenario.
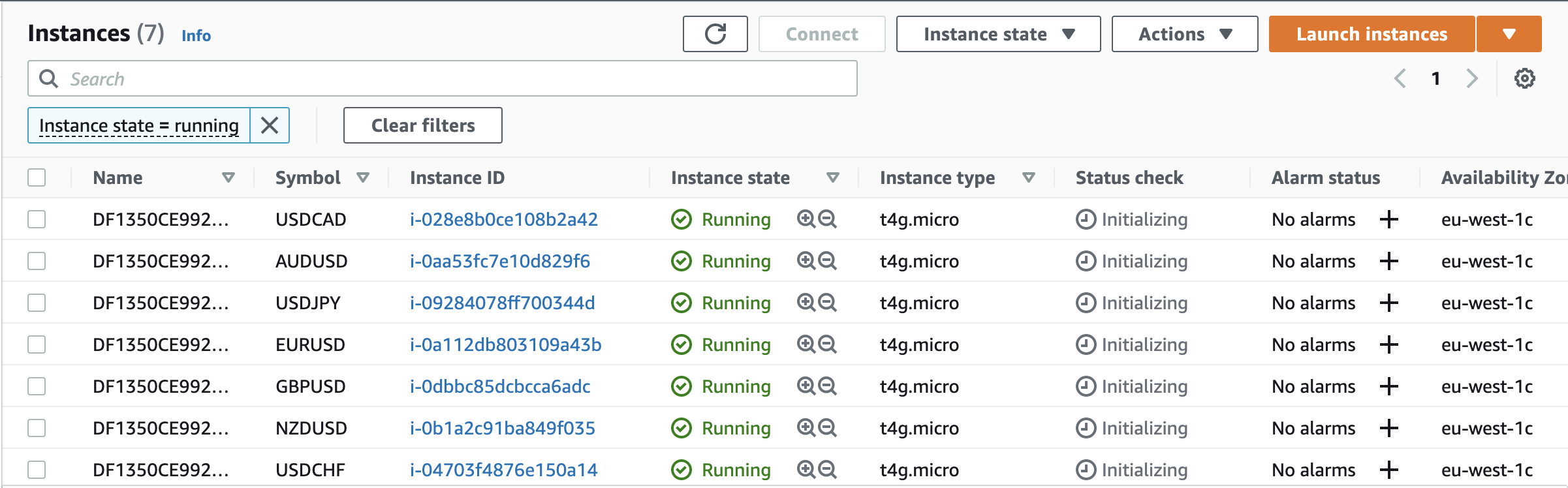
Next
The engine is constantly being improved and updated, though it’s in a good state to start focusing on trading strategies. You can check out my first experiment, You can check out my first experiment, Random Walk Theory.
If you’ve got any feedback on this post please let me know ryan@mccaffers.com